Flux.1 Kontext 논문 리뷰
FLUX.1 Kontext: Flow Matching for In-Context Image Generation and Editing in Latent Space
arxiv
Labs, B. F., Batifol, S., Blattmann, A., Boesel, F., Consul, S., Diagne, C., … & Smith, L.
Black Forest Labs
25.06
Abstract
FLUX.1 Kontext: “a generative flow matching model”
하나의 통합된 아키텍처를 사용하여 image generation 과 editing 기능을 통합함.
텍스트와 이미지 입력의 semantic 맥락을 통합하여 생성함.
캐릭터 일관성 및 안정성이 향상됨.
KontextBench: local editing, global editing, character reference, style reference and text editing 5가지 분야의 1026 이미지-프롬프트 쌍을 포함하는 벤치마크 발표함.
1. Introduction
Local editing
특정 영역만 수정하고, 나머지 영역은 유지하는 것.
- 예: 배경은 보존하고 자동차 색상만 변경, 피사체를 유지하고 배경만 수정함.
inpainting 으로 구현함.
LaMa, Latent Diffusion inpainting, RePaint, Stable Diffusion Inpainting variants, FLUX.1 Fill, Palette, Paint-by-Example 연구가 진행되었음.
ControlNet 은 mask 를 주어 수정을 하거나, DragGAN 은 특정 포인트 기반으로 사용자가 직접 수정할 수 있음.
Generative editing
시각적 콘셉(특정 도형이나 로고)을 추출해 새로운 환경에서 충분히 재현하며, 새로운 시각으로 합성하거나 새로운 시각적 맥락에서 렌더링함.
LLM 에서 in-context learning 과 유사하게 네트워크는 파라미터 업데이트 없이 프롬프트에 제공된 예시로 부터 task를 학습하고, generator는 conditioning context 에 따라 실시간으로 출력을 조정함.
- 개인화(personalization)을 가능하게 하고, 이도 파인튜닝이나 LoRA 학습없이 가능함.
IP-Adapter, retrieval-augmented diffusion variants 연구가 초기에 진행되었음.
최신 연구들의 한계점
합성 쌍(synthetic pairs)으로 학습된 instruction 기반 방법은 생성 파이프라인의 한계점을 그대로 이어받기 때문에 편집의 다양성, 현실성이 제한됨.
여러 편집을 거치게 되면 인물, 사물의 정확한 외형 모습을 유지하는 것이 어려움.
LLM에 통합된 autoregressive editing 모델은 denoising 기반 방법에 비해 품질이 낮고, 대체로 긴 inference 시간으로 인해 사용하기 어려움.
FLUX.1 Kontext solution
context 와 instruction 토큰을 concat해서 타겟의 속도 예측을 학습하는 flow 기반 생성 모델로, 성능이 높아지고 한계를 극복했음.
Contribution
Character consistency: 다수의 캐릭터 유지 가능 및 여러 차례 편집에도 우수함.
Interactive speed: 1024x1024 이미지를 3~5 초안에 수행 가능함.
Iterative application: 여러 차례 연속적으로 편집을 통해 정교하게 이미지 수정이 가능함.


2. FLUX. 1
FLUX.1 은 rectified flow transformer 모델이며 image autoencoder 의 latent space 에서 학습함.
adversarial objective 를 가지고 convolutional autoencoder 학습 방식(Rombach et al.)을 따랐음.
학습 computing을 확장하고, 16 latent 채널을 사용하여 관련 모델에 비해 reconstruction 성능을 향상시켰음.
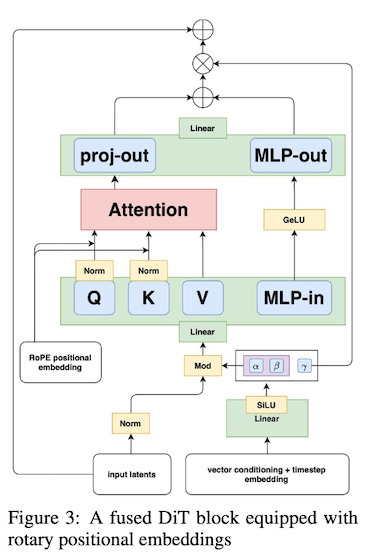
double stream 과 single stream 블록을 사용했음.
double stream 블록은 이미지와 텍스트 토큰에 대해 별도의 weights 를 가지고 있고, 토큰이 concat을 하고, attention 연산을 적용함으로써 mixing 이 수행됨.
그 후, concat 및 이미지와 텍스트 토큰에 38 single stream 블록을 적용함.
텍스트 토큰을 버리고, 이미지 토큰만을 디코딩함.
GPU 사용을 향상시키기위해, single stream 블록에서 fused feed-forward 블록 사용함.
feed-forward 블록 내 파라미터 수를 2배로 감소시키고,
MLP 의 linear 레이어와 attention 입출력을 융합해 더 큰 행렬 벡터 곱셈을 유도함으로써 더 효율적인 학습, 추론을 가능하게 함.
분해된 3차원 회전 위치 임베딩(3D RoPE)을 활용하고, latent 토큰은 시공간 좌표로 인덱싱되며 회전 위치 임베딩을 활용함.)
Flux vs Diffusion model
Flux Diffusion 핵심 방법론 Rectified Flow noise ε 예측 네트워크 내부 구조 Double/Single-stream transformer block U-Net + attention - Rectified Flow / Flow Matching 도입
일반 diffusion model 은 noise ε 를 예측하는 reverve process 를 학습함.
Flux 는 rectified flow의 flow matching 방식으로 학습함.
데이터 분포를 타겟 분포(가우시안)으로 연결하는 연속적인 변환 경로(flow)를 정의하고, 그 경로를 따라가는 vector field 를 학습함.
특히, 경로를 최단 경로인 직선 경로로 타겟으로 설정하여 단순한 vector field 로 학습하게 유도함.
Transformer 구조
Double/Single-stream block 의 혼합 구조로 구성됨.
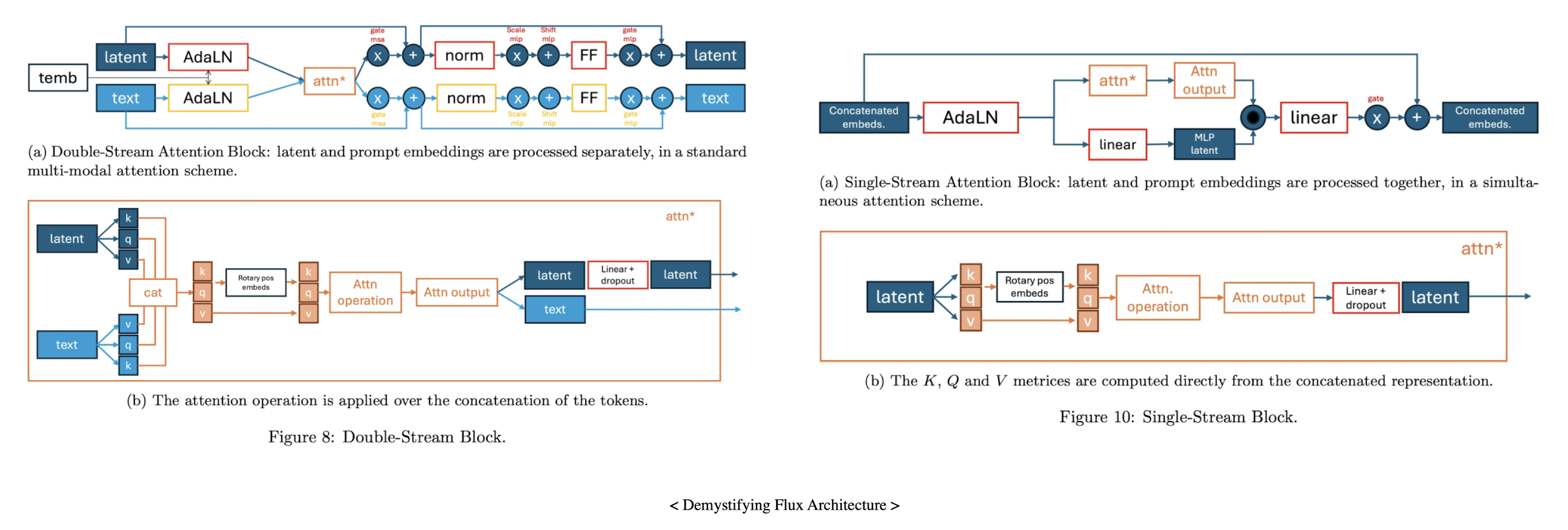
Double-stream block 은 latent 와 text token 간 별도의 weight 를 사용하고, 결합하여 attention 을 진행함.
Single-stream block 은 latent 와 text token 이 concat 되어 공유된 weight 를 사용하고, attention 을 진행함.
- Rectified Flow / Flow Matching 도입
3. FLUX.1 Kontext
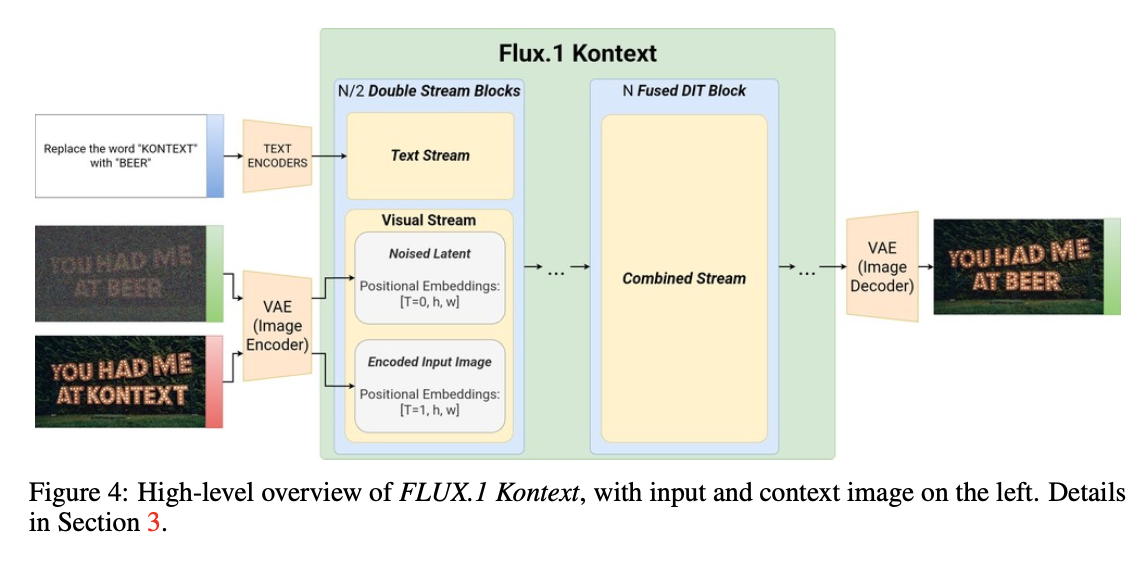
텍스트 프롬프트와 레퍼런스 이미지를 jointly 하게 condition된 이미지를 생성하는 모델을 학습하는 것이 목표임.
conditional 분포, $p(x \mid y, \ c)$를 근사하는 것이 목표임.
$x$ (타겟 이미지), $y$ (context image or ∅), $c$ (텍스트 프롬프트) 로 정의함.
이를 통해 동일한 네트워크로 $y$ 가 주어졌을 때(context image), 이미지 기반 편집을 수행하고,
- $y$ 가 주어지지 않았을 때(∅), 완전히 새로운 콘텐츠를 생성할 수 있게함.
즉, $x$ (output 이미지), $y$ (context 이미지 or ∅), $c$ (텍스트 프롬프트) 일 때,
우리는 conditional 분포를 모델링함 → $p_θ(x \mid y, \ c)$
$y$ 가 주어졌을 때, context 기반 로컬 편집을 처리하고, $y$ 가 주어지지 않았을 때, free T2I 로 생성하도록 처리함.
$\text{FLUX.1}$ T2I 체크포인트로 부터 학습을 시작하여, 최적화를 위해 수백만 개의 관계 쌍을 수집하고 선별함.
Token sequence construction
이미지는 frozen $\text{FLUX}$ autoencoder 로 latent 토큰으로 인코딩됨.
context image 토큰 $y$ 는 이미지 토큰 $x$ 에 append 후, 모델의 visual stream 에 입력됨.
sequence concatenation 은 다양한 입출력 해상도 및 비율을 처리할 수 있고, 쉽게 여러 이미지 $y_1, y_2, … , y_N$ 으로 확장될 수 있음.
채널 축으로 concat 을 실험했으나 성능이 좋지 못했음.
3D RoPE 임베딩으로 positional information 을 인코딩함.
context $y$ 에 대한 임베딩은 모든 context 토큰에 대해 일정한 offset을 받음.
offset 을 virtual time step 으로 설정하여 context 블록과 target 블록을 명확히 분리하면서 내부 공간 구조는 그대로 유지했음.
token position 을 $u = (t, h, w)$ 로 표시할 때,
target token: $u_x = (0, h, w)$ 로,
context token: $u_{y_i} = (i, h, w), i = 1, …, N$ 로 설정함.
Rectified-flow objective
train loss: rectified flow-matching loss.
\[\begin{equation} \mathcal{L}_\theta=\mathbb{E}_{t \sim p(t), x, y, c}\left[\left\|v_\theta\left(z_t, t, y, c\right)-(\varepsilon-x)\right\|_2^2\right] \end{equation}\]$z_t$ : $x$ 와 noise $\epsilon$ 을 선형보간한 latent → $z_t = (1−t)x+ tε$
$p(t; µ,σ= 1.0)$ 에 대한 logit normal shift schedule 사용 (Appendix A.2 참고)
$y=∅$ 일 때, 모든 토큰 $y$ 를 생략해 모델의 T2I 생성 능력을 보존함.
Adversarial Diffusion Distillation
학습된 flow matching model 의 샘플링 방법은 일반적으로 50~250 회의 유도된 네트워크 평가를 사용해 oridinary 또는 stochastic differential equation 을 해결하는 것을 포함함.
단점
multi-step 샘플링은 속도가 느려 모델 서빙에 비용이 많이 들고 low-latency 에 적합하지 않음.
guidance 는 가끔 over-saturated 샘플과 같은 아티팩트를 발생시킬 수 있음.
저자들은 latent adversarial diffusion distillation(LADD) 를 활용하여 두 단점을 해결할 수 있다고 함.
- adversarial 학습으로 샘플링 스텝 수를 줄이면서 품질을 향상시킬 수 있었음.
Implementation details
pure T2I 체크포인트를 로드하여, I2I 와 T2I task 를 jointly 하게 모델을 파인튜닝한다.
자연스럽게 다수 입력 이미지를 다룰 수 있지만, 단일 context image 에 대한 conditioning 을 집중했음.
$\text{FLUX.1 Kontext [pro]}$ 는 flow objective 로 학습 후 LADD 를 적용함.
$\text{FLUX.1 Kontext [dev]}$ 는 guidance-distillation 을 적용해 12B diffusion transformer 를 얻을 수 있음.
$\text{FLUX.1 Kontext [dev]}$ 를 edit task 에 최적화하기 위해, I2I 학습에만 집중했음.
즉, T2I 학습은 진행하지 않았음.
4. Evaluations & Applications
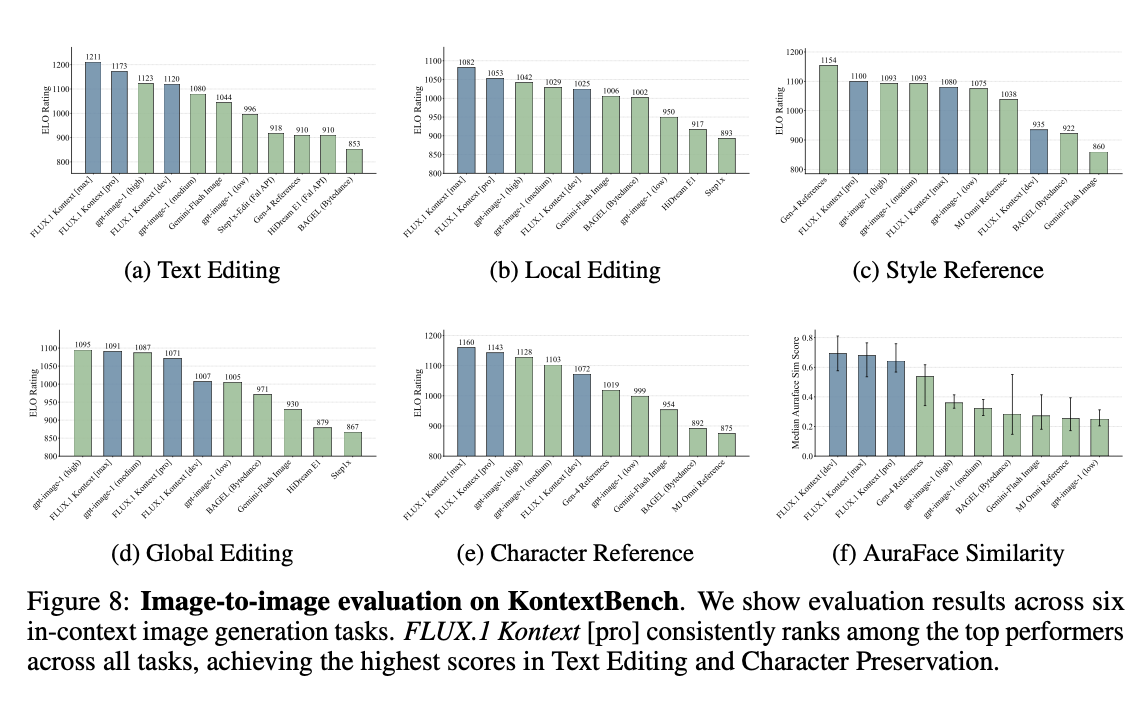
KontextBench
개인 사진, CC 라이센스 예술 작품, public domain 이미지, AI 생성 이미지로 부터 108 개 데이터에서 파생된 이미지-프롬프트 1026 쌍으로 구성함.
5개 task 로 구분: local instruction editing (416 개), global instruction editing (262 개), text editing(92 개), style reference (63 개), and character reference (193 개)
Inference latency
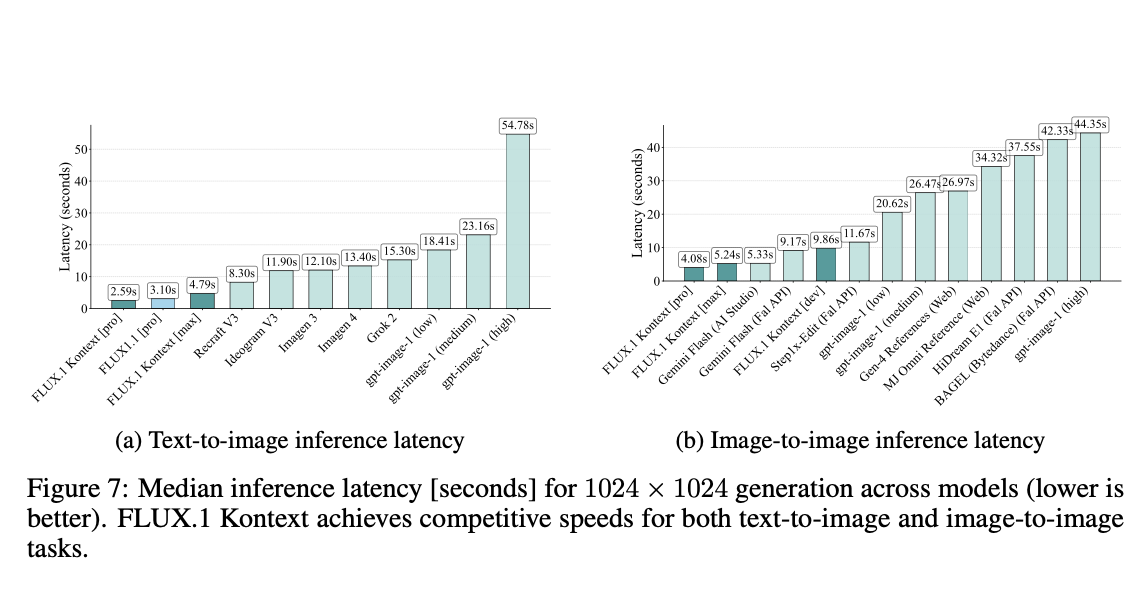
I2I (사람 선호도 평가)
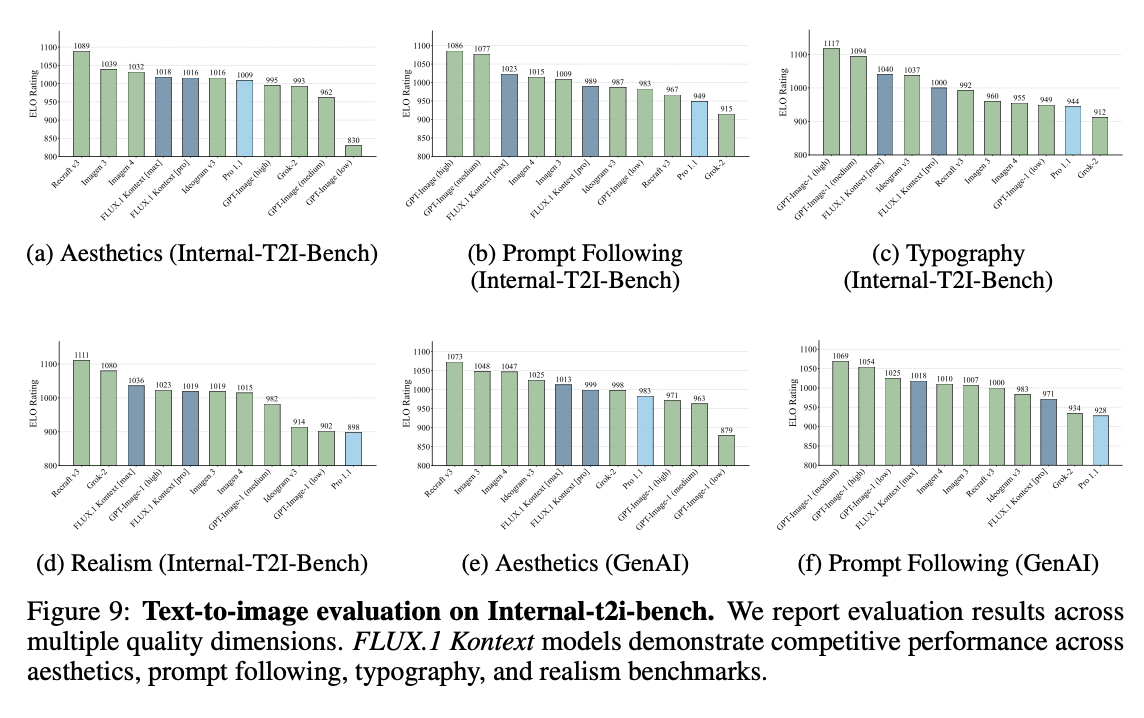
T2I (사람 선호도 평가)
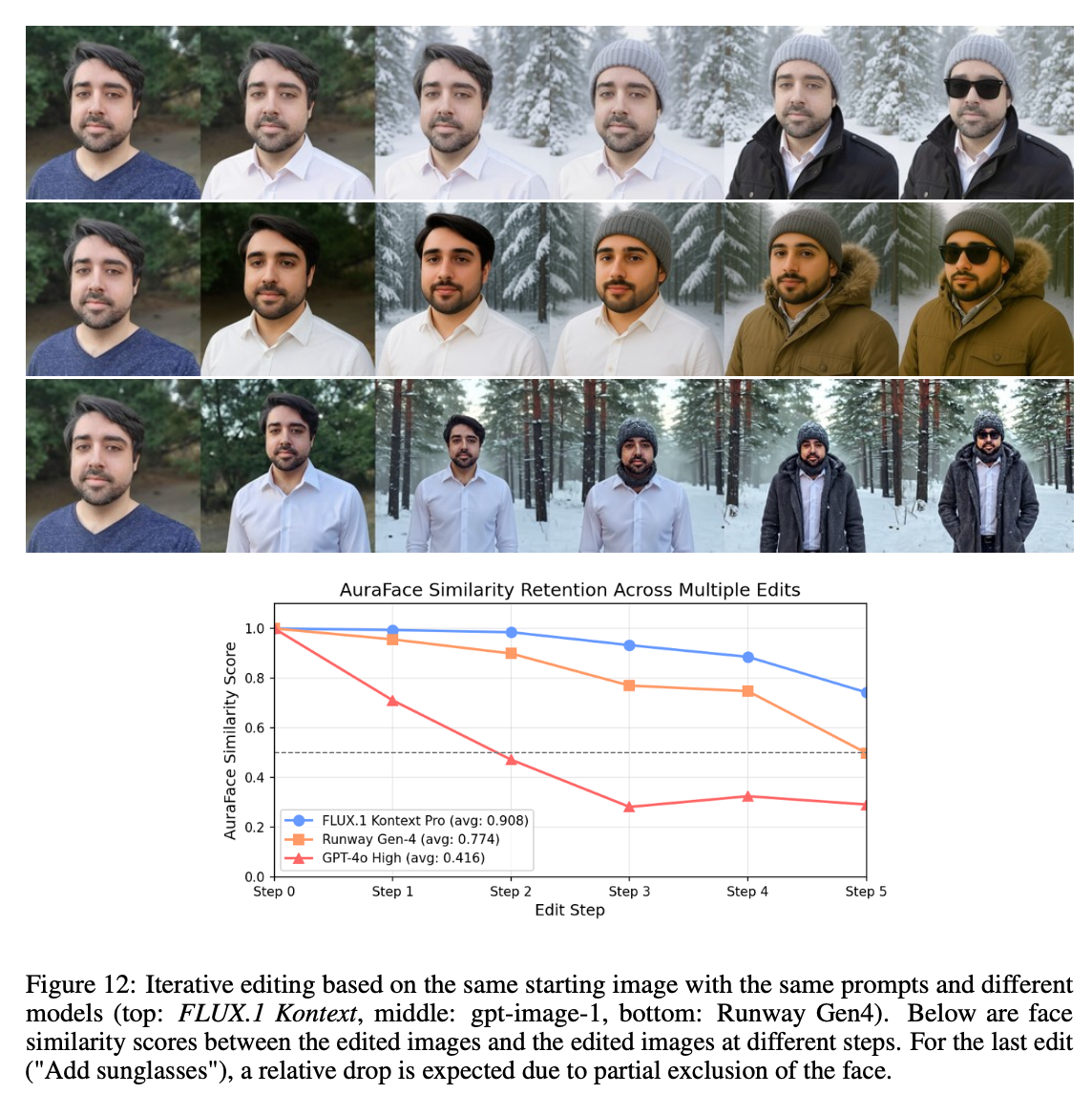
4.3 Iterative Workflows
- 캐릭터 및 객체의 일관성을 유지하는 평가 지표를 AuraFace 임베딩의 코사인 유사도를 계산함.


- Runway Gen-4, GPT-4o 보다 높은 AuraFace 유사도 달성
4.4 Specialized Applications
- style reference

- visual cue-based editing

- bakeyness: 과도한 채도, 중심 피사체에 대한 과도한 집중, 뚜렷한 bokeh 효과, 특유의 “AI 미학”을 선호하는 경향

Limitations
multi-turn editing 은 이미지 품질을 저하시키는 아티팩트 유발할 수 있음.
특정 프롬프트 요구 사항을 무시하며 따르지 않을 수 있음
distillation 과정이 시각적 아티팩트를 유발할 수 있음.
